L'entropie d'une lettre dans un texte quelconque, en supposant que
l'alphabet comporte 26 symboles, est de
![]() .
Ceci est une première approximation, en supposant que toutes les lettres
sont générées au hazard. Cependant, il s'agit ici d'un texte réel,
et chaque lettre a une fréquence d'appartition indépendante des autres.
Par exemple, le « e » est plus souvent utilisé que le « z »,
comme pourrait l'indiquer un tableau des fréquences d'apparition des
lettres dans une langue donnée, lequelle aura été construit à partir
de l'analyse de milliers de pages de texte standard. Le tableau 2
est un exemple d'un tel tableau. Grâce à ce tableau des fréquences,
on trouve que l'entropie du français
.
Ceci est une première approximation, en supposant que toutes les lettres
sont générées au hazard. Cependant, il s'agit ici d'un texte réel,
et chaque lettre a une fréquence d'appartition indépendante des autres.
Par exemple, le « e » est plus souvent utilisé que le « z »,
comme pourrait l'indiquer un tableau des fréquences d'apparition des
lettres dans une langue donnée, lequelle aura été construit à partir
de l'analyse de milliers de pages de texte standard. Le tableau 2
est un exemple d'un tel tableau. Grâce à ce tableau des fréquences,
on trouve que l'entropie du français ![]() est d'environ 3,954
bits.
est d'environ 3,954
bits.
|
|
L'information fournie par la position d'une lettre dans une phrase
et ses relations avec les autres lettres est encore plus grande que
la simple probabilité d'une lettre individuelle. Par exemple, un « q »
est souvent suivi d'un « u ». L'entropie calculée sur l'ensemble
des ![]() digrammes5 possibles devrait donc être plus faible que celle des lettres simples.
On peut faire l'approximation que l'entropie de l'anglais claculée
selon les digrammes est la moitié de celle calculée selon les monogrammes
(voir section 4.1.3 pour des valeurs exactes). On
peut étendre cette approximation aux
digrammes5 possibles devrait donc être plus faible que celle des lettres simples.
On peut faire l'approximation que l'entropie de l'anglais claculée
selon les digrammes est la moitié de celle calculée selon les monogrammes
(voir section 4.1.3 pour des valeurs exactes). On
peut étendre cette approximation aux ![]() -grammes et définir la distribution
-grammes et définir la distribution
![]() de tous les
de tous les ![]() -grammes de texte clair possible
dans un langage
-grammes de texte clair possible
dans un langage ![]() . Cela donnerait, lorsque
. Cela donnerait, lorsque ![]() tend vers l'infini,
tend vers l'infini,
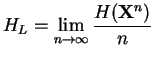
L'entropie est importante en cryptographie. Il est important de tendre vers une entropie la plus grande possible, puisqu'une grande entropie est associée à une grande incertitude sur le texte clair lorsqu'on a déchiffré une partie du texte chiffré. Les techniques modernes de chiffrement produisent un texte chiffré indiscernable d'un texte aléatoire.